Bruker ProteoScape™
结果即时呈现
实时结果 = 效率

实时搜库结果可协助用户监控当前仪器及样本状态
拥有实时搜库和智能采集平台的 4D-蛋白质组学技术
Bruker ProteoScape™ 整合的实时搜库和智能采集功能打破了数据分析的瓶颈
通用性
- Bruker ProteoScape™ 支持所有timsTOF Pro 2、HT、fleX 和 SCP 平台的数据。
4D-蛋白质组学
- 尽管 CCS 维度信息的加入使得数据量增大,但 Bruker ProteoScape™ 的实时搜库功能能够应对大数据带来的挑战,即使包括像磷酸化在内的多种翻译后修饰同时检索,实时搜库功能也能轻松应对
GPU 支持的海量数据并行计算
- Bruker ProteoScape™ 基于 GPU 计算,可提供数以千计的 CUDA 核心并行处理数据。
Bruker ProteoScape™ 数据查看
- 从高水平实验信息到目标特定碎片离子谱图,Bruker ProteoScape™ 实现在集成视图中查看数据的全部细节信息。
智能化
- Bruker ProteoScape™ 可以智能化决定样本队列分析进程,每个样本采集结束时,通过将实验结果与预设的蛋白质或肽段鉴定数量标准对比,来决定样品队列继续与否。该功能可核验方法的适用性、节省稀有样本、昂贵耗材和机时。


节省时间和成本
- 安心上机稀有样本
- 高效利用珍贵机时
- 避免浪费高成本样本
- 无需再耗时等待 QC 结果来确定系统适用性
- 方法开发过程中无需等待搜库结果

“ 创新的软件工具对于解决基于质谱的未知生物学问题是必要的。timsTOF Pro 平台采用的捕集离子淌度技术及仪器稳健性为采用 Bottom-up 蛋白组学的多疾病探索性研究方面提供了独一无二的解决方案。”
Professor John Yates III, the Ernest W. Hahn Professor at The Scripps Research Institute in La Jolla, California
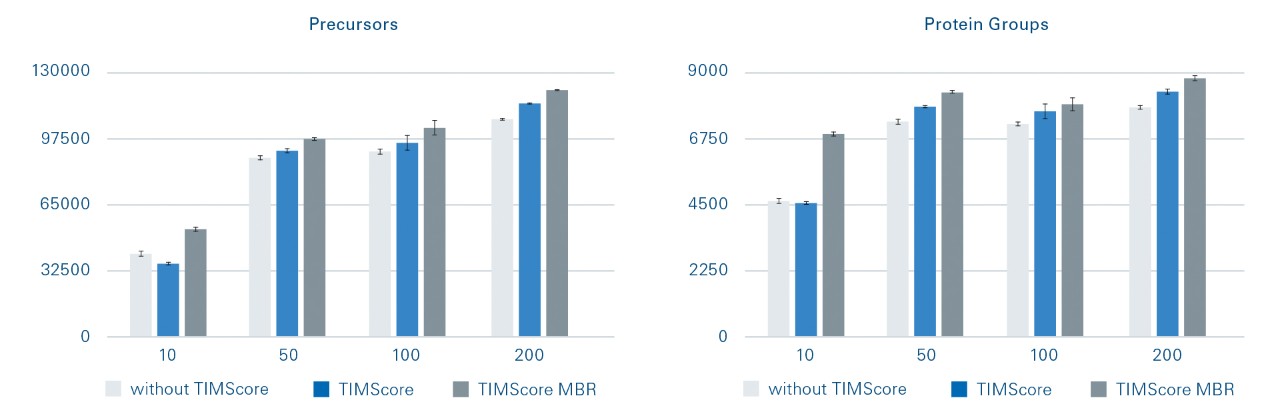
TIMScore™ ——通过机器学习和 CCS 来获得更好的 FDR
TIMScore™ 引入 CCS 维度来为 4D-蛋白质组学提供更高的 PSM ( peptide-spectrum Match )、肽段和蛋白质鉴定数量。
Bruker ProteoScape™ 搜索引擎将 CCS 测量值与预测值进行比较,并计算出每张谱图对应的前五个候选肽段的 TIMScore 值。
TIMScore 的优势体现在肽段验证和 FDR ( False Discovery Rate ) 评估中,在不支持 CCS 值的算法中,目标肽段和候选肽段基于 1% 误差进行的判定 ( Panel A )。而支持 CCS 值的 TIMScore 算法中,候选肽段可在三个维度上矢量化,从而能够通过可显著区分的等值平面来进行 1% 误差卡控 ( Panel B )。
使用等值平面判定可提高准确性和精确度,有助于验证以前在传统二维数据中评分不佳的 PSM。


TIMSrescore™ —— 基于机器学习、数据驱动的 dda-PASEF® 数据重新打分流程
布鲁克 ProteoScape™ 软件中的 TIMSrescore™ 工作流程允许用户使用基于 timsTOF 数据训练并优化的机器学习预测模型 tims2rescore 进行 CCS 值、保留时间和碎片离子的强度的预测,最大限度地提高 dda-PASEF 采集数据的解析深度。
该软件将全新的 timsTOF 谱图预测模型 MS2PIP、基于深度学习的新型肽段离子淌度预测工具 IM2Deep、保留时间预测工具 DeepLC 以及 Mokapot 相组合,实现了超高灵敏度的肽段鉴定,让用户能够在相同错误发现率(FDR)情况下获得更多的多肽鉴定结果。
TIMSrescore™ 工作流程非常适合具有挑战性的蛋白质组学数据解析,如翻译后修饰、蛋白质基因组学和免疫肽组学。
更多信息:


“ 我和我的团队很高兴在过去 5 年中我们的 MS2rescore 重打分工作流程在蛋白质组学领域中被广泛应用。目前通过与布鲁克的合作,该流程已集成至ProteoScape 软件中,我们很高兴能够将 MS2rescore 拓展到更多的 timsTOF 用户中去,这让我们先进的、基于机器学习的信息学方法能够帮助生命科学研究人员最大限度地发挥其蛋白质组学数据的价值。”
Lennart Marten, Ph.D., Associate Department Director Bioinformatics at VIB – U of Ghent Center for Medical Biotechnology, Ghent, Belgium
BPS Novor —— PASEF® 扫描速度下的从头测序
为进一步推进免疫肽组学、宏蛋白组学及其他更多基于从头测序模式的应用,我们与 Rapid Novor Inc. 联合开发了 BPS Novor。这在充分发挥实时搜库功能的基础上为 timsTOF 数据获取快速精准的从头测序分析结果提供了解决方案。
BPS Novor 通过训练和优化 timsTOF 采集的 1,780,000 多张谱图,包括各种各样非酶切谱图,从而构建了一个广义打分模型。这个模型每秒能处理超过 1000 张谱图,时期能够分析 timsTOF 产生的实时从头测序数据。BPS Novor 在各种各样数据类型上能够持续保持并优于 Novor 软件标准。
BPS Novor 在酶切特异性或物种上没有明显的偏好性,且比速度上比其他软件快 20 倍。
通过与 timsTOF 平台的 PASEF 扫描技术结合,Bruker ProteoScape™ 和 BPS Novor 为一系列免疫肽组学从头测序数据的实时搜库提供了高灵敏度的应用方案。



“ 多年来从头测序已经成为我们实验室研究的重要组成部分,开发出一种在兼顾采集速度的同时准确传递结果的算法意味着能够实现大规模免疫肽组学样品实时分析。这也代表我们团队可以将研究成果快速落地,并且在史无前例的时间尺度上推进该工作流和临床研究结合。”
Professor Anthony W. Purcell, Head of Immunoproteomics Laboratory, Monash University, Melbourne, Australia
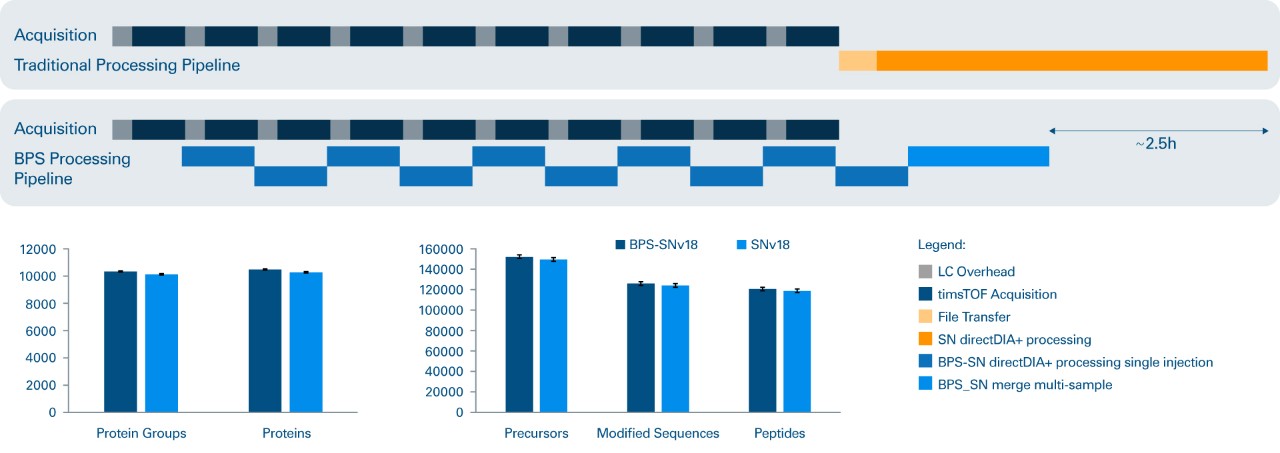
Spectronaut directDIA+ 工作流集成到 Bruker ProteoScape™ 软件
Bruker ProteoScape™ (v >2024b) 集成了 Spectronaut 的模块,支持用户使用 directDIA+ 工作流进行非依赖库的 dia-PASEF® 分析。这将高效的实时搜库流程与高灵敏度和定量准确性的 DIA 分析黄金标准流程进行了充分的结合。
BPS 采用相同的数据流机制,将数据从采集电脑实时传输至搜库服务器。采集结束后触发用户自定义的 directDIA+ 工作流程完成对 dia-PASEF® 数据的无库分析。这种自动化在逐针进样流程的基础上为用户提供了进行数据质量探索和验证的机会。
项目结束时,用户可以对整个项目数据进行定量分析,以获得整个项目的错误率卡控结果。用户还可以下载 SNE 文件(单针搜库或整个项目搜库的文件),并将其导入独立的 Spectronaut 中进行详细的可视化、后处理和定制报告。
借助 TIMS DIA-NN 简化 Bruker ProteoScape™ 上的 dia-PASEF® 分析流程
Bruker ProteoScape™ 能够利用 Lilley、Rasler 和 Demichev 实验室研发的 DIA-NN 软件(基于神经网络 的DIA算法) 的定制版本进行 dia-PASEF® 工作流分析。
TIMS DIA-NN 实现了可靠的、稳健的和定量准确的大规模实验。Bruker ProteoScape™ 采用了实时分析工作流,将从采集电脑实时传输到 Bruker ProteoScape™ 服务器上的 dia-PASEF® 数据进行分析和存储。采集结束时会触发谱图库搜索,并记录搜索结果。TIMScore™ 驱动的 DDA 搜索结果可轻松用于谱图库,也支持其他常用工具导入谱图库。
项目采集结束时用户可运行MBR功能来实现整个项目数据的定量分析。这为用户提供了 进行 PASEF® 和 dia-PASEF® 数据分析的集成环境
更多信息:

“ 通过与布鲁克公司合作,让 DIA-NN 处理 dia-PASEF 数据变的流程化,并可利用 CCS 值,这是非常有用的。这让非常短的梯度里鉴定和定量几千种蛋白质变得简单和快速。DIA-NN 的供应商整合版即 TIMS DIA-NN 已经成为Bruker ProteoScapeTM 生物信息平台的一部分,我们对与布鲁克合作产生的这一成果感到非常高兴。”
Prof. Dr. Markus Ralser, Einstein Professor of Biochemistry at Charité, Berlin, Germany
小于 5ms 进行全库检索
超高搜索速度获取无损搜库结果。
A) 人源细胞裂解样品多次重复 DDA 采集结果在 Bruker ProteoScape™ 和 MaxQuant 上的蛋白鉴定结果比较
B) 人源细胞裂解样品多次重复 DDA 采集结果在 Bruker ProteoScape™ 和 MaxQuant 上的肽段鉴定结果比较
C) Bruker ProteoScape™ 和 MaxQuant 搜库结果中蛋白一致性达 97%,肽段一致性达 90%
更多信息:

Bruker ProteoScape™ 对同一数据的实时搜库获取结果与离线模式搜索结果一致。由于 Bruker ProteoScape™ 是基于 GPU 的搜库算法,因此相比于 CPU 其运行时间可忽略不计。除此之外,Bruker ProteoScape™ 也为需要更大检索空间的特定应用( 如 PTM ) 提供可行性。
Bruker ProteoScape™ 建立的搜库标准与 DDA 搜库金标准水平相当,甚至更好。
实时数据库检索大大节约非标记定量流程时间
利用实时鉴定,通过运行间匹配 ( MBR ) 大幅减少 dda-PASEF 无标记定量 ( LFQ ) 所需的时间。
- TIMScore 引入 CCS 维度提升蛋白鉴定量
- 一般来说,数据定量时间仅需采集时间的 1/20
- Bruker ProteoScape™ 可大大节约数据分析时间
凭借 Bruker ProteoScape™ 运行即结束 ( Run & Done ) 功能,在定量流程前,就能够识别数据质量差的样本并重新进行数据采集。Bruker ProteoScape™ 基于淌度 ( IM ) 过滤的提取离子流图 ( XIC ) 定量流程是根据 Census 算法
( https://doi.org/10.1002/0471250953.bi1312s29 ) 开发的。

视频

“ Bruker ProteoScape 在 timsTOF Pro 上的实时搜库结果为我们节省了大量时间。它使得我们能够实时开发方法、监测液相和质谱仪器的运行状态以及提升整体效率。”
Sebastian Vaca, Ph.D., Research Scientist, Proteomics Platform at the Broad Institute of MIT and Harvard (Carr Lab), Cambridge, USA








仅供研究使用。不适用于临床诊断程序。